2014/05/29(木)Perl Data Language 統計編 #03 「累積相対度数グラフ」
データ↓
http://www.tokyo-tosho.co.jp/download/DL02122.zip
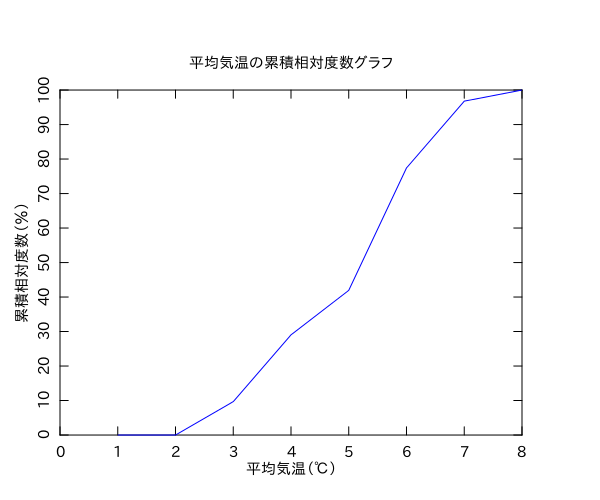
問1.1の4)はPDL::IO::Misc::rcols でCSVファイルから平均気温のデータのとこだけ抜き出して、相対度数を計算してグラフに出力という流れです。
#!/usr/bin/env perl
use strict;
use warnings;
use feature qw/say/;
use PDL::Lite;
use PDL::IO::Misc ();
use PDL::Graphics::PLplot;
use DDP filters => { -external => [ 'PDL' ] };
my $infile = 'weather.csv';
my $colnum = 1;
my $heikin_kion_list = PDL->rcols($infile, { COLSEP => ',', INCLUDE => '/[0-9]/' }, $colnum);
my $kion_list = pdl [ int($heikin_kion_list->min) - 1 .. int($heikin_kion_list->max) + 1 ];
my $num_elem = $heikin_kion_list->nelem;
my @sotai_freq_list;
for my $kion ($kion_list->list)
{
my $sotai_freq = $heikin_kion_list->where($heikin_kion_list <= $kion)->nelem / $num_elem * 100;
push(@sotai_freq_list, $sotai_freq);
}
my $pl = PDL::Graphics::PLplot->new(
DEV => 'xcairo',
TITLE => '平均気温の累積相対度数グラフ',
XLAB => '平均気温(℃)',
YLAB => '累積相対度数(%)',
XTICK => 1,
NXSUB => 1,
YTICK => 10,
NYSUB => 1,
COLOR => 'BLUE',
);
my $sotai_freq_list = pdl @sotai_freq_list;
$pl->xyplot($kion_list, $sotai_freq_list, BOX => [ 0, $kion_list->max, 0, 100 ]);
$pl->close;
2014/05/29(木)Perl Data Language 統計編 #02 「度数分布表と棒グラフ」
http://www.tokyo-tosho.co.jp/download/DL02122.zip
↑のデータを使って実際の問題も解いていきましょう。まずは第1章の練習問題の2)から。
度数分布表はPDLを使わずにテキストで出力しました。 CSVの読み込みは「PDL::IO::Misc」でできるのですが、CSV中の文字列が値ゼロになるので、文字列を含む場合はText::CSVあたりで読み込まざるをえないですね。(このへんはRに比べると少し不便)
#!/usr/bin/env perl
use strict;
use warnings;
use feature qw/say/;
use utf8;
use open qw/:encoding(utf-8) :std/;
use Text::CSV;
use Text::UnicodeTable::Simple;
use PDL::Lite;
use PDL::Graphics::PLplot;
use DDP filters => { -external => [ 'PDL' ] };
my $infile = 'weather.csv';
my $csv = Text::CSV->new({
auto_diag => 1,
binary => 1,
});
open(my $fh, '<:encoding(cp932)', $infile) or die $!;
my $kaze_cnt = 0;
my %kaze_direction_freq_of;
while ( my $row = $csv->getline($fh) )
{
my ($hizuke, $kion, $shitsudo, $nissho, $kaze_direction) = @{ $row };
next unless $hizuke =~ /^[0-9]+$/;
$kaze_direction_freq_of{$kaze_direction}++;
$kaze_cnt++ if defined $kaze_direction;
}
close($fh);
my $table = Text::UnicodeTable::Simple->new;
$table->set_header(qw/風向き 度数 相対度数/);
for my $direction (keys %kaze_direction_freq_of)
{
my $freq = $kaze_direction_freq_of{$direction};
$table->add_row( $direction, $freq, sprintf("%.3f", $freq / $kaze_cnt) );
}
say '度数分布表:';
say $table;
say '(相対度数は少数第三位まで表示)';
my $pl = PDL::Graphics::PLplot->new(
DEV => 'xcairo',
XLAB => '風向き',
YLAB => '度数',
YTICK => 2,
NYSUB => 2,
COLOR => 'BLUE',
);
my @labels = keys %kaze_direction_freq_of;
my $values = pdl map { $kaze_direction_freq_of{$_} } @labels;
$pl->bargraph(@labels, $values, BOX => [ 0, scalar @labels, 0, $values->max + 1 ]);
$pl->close;
度数分布表:
.--------+------+----------.
| 風向き | 度数 | 相対度数 |
+--------+------+----------+
| 南東 | 1 | 0.032 |
| 西北西 | 2 | 0.065 |
| 東北東 | 2 | 0.065 |
| 南西 | 1 | 0.032 |
| 北西 | 10 | 0.323 |
| 北北西 | 15 | 0.484 |
'--------+------+----------'
(相対度数は少数第三位まで表示)

2014/05/29(木)Perl Data Language 基礎編 #09 「PDL::Lite と PDL::LiteF」
「use PDL::Lite」が以下と同等
use PDL::Core '';
use PDL::Ops '';
use PDL::Primitive '';
use PDL::Ufunc '';
use PDL::Basic '';
use PDL::Slices '';
use PDL::Bad '';
use PDL::Version;
use PDL::Lvalue;
「use PDL::LiteF」が以下と同等
use PDL::Core;
use PDL::Ops;
use PDL::Primitive;
use PDL::Ufunc;
use PDL::Basic;
use PDL::Slices;
use PDL::Bad;
use PDL::Version;
use PDL::Lvalue;
違いはサブルーチンをエクスポートするか否か。
できるだけ名前空間を汚したくないので、今後は「PDL::Lite」を使っていきます。
ちなみに「use PDL」は以下と同等
use PDL::Core;
use PDL::Ops;
use PDL::Primitive;
use PDL::Ufunc;
use PDL::Basic;
use PDL::Slices;
use PDL::Bad;
use PDL::MatrixOps;
use PDL::Math;
use PDL::Version;
use PDL::IO::Misc;
use PDL::IO::FITS;
use PDL::IO::Pic;
use PDL::Lvalue;
2014/05/28(水)Perl Data Language グラフィック編 #01 & 統計編 #01 「PDL::Graphics::PLplotのインストールとヒストグラムの描画
PDLのグラフ描画ライブラリは↓のようにいろいろあります。
PDL::Graphics::Gnuplot
PDL::Graphics::PGPLOT
PDL::Graphics::Prima
PDL::Graphics::PLplot
PGPLOTはまともにインストールできなかったので、「The PDL Book」に載っていてライセンスがLGPLで速度も問題なさそうなPLplotを選択しました。
スライドシェアに資料もあります。「https://www.slideshare.net/dcmertens/p-lplot-talk」
使う前にまずは、plplotをインストールする必要があります。以下のコマンドでインストールできます。
sudo apt-get install libplplot11
sudo apt-get install libplplot-dev
(↑がないと PDL::Graphics::PLplot インストール時に libplplotd.so がないと怒られる)
sudo apt-get install libplplot-driver-cairo
sudo apt-get install libplplot-driver-xwin
cpanm PDL::Graphics::PLplot
libplplotのドライバーはいろいろあるので、インストールして試してみるといいかもです。
グラフ描画は↓のような感じです。
DEVオプションはいろいろ指定できるけど、ウィンドウに表示するならUnicode対応の「xcairo」がキレイで日本語も表示できてオススメです。Max OSだとAquaTerm Driverっていうドライバーもあるようです。
#!/usr/bin/env perl
use strict;
use warnings;
use feature qw/say/;
use PDL;
use PDL::Graphics::PLplot;
use DDP filters => { -external => [ 'PDL' ] };
my $pl = PDL::Graphics::PLplot->new(
DEV => 'xcairo',
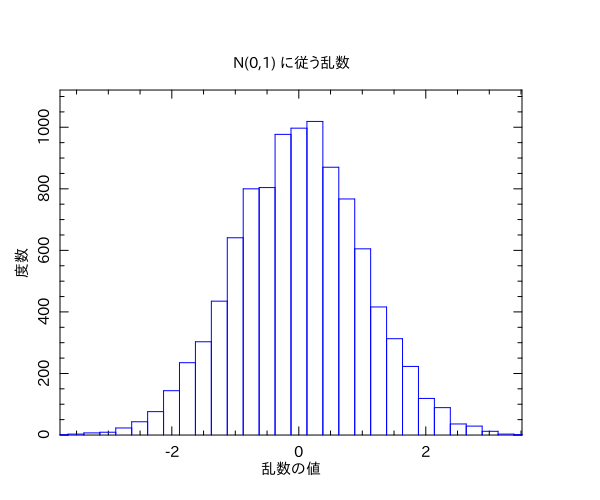
TITLE => 'N(0,1) に従う乱数',
XLAB => '乱数の値',
YLAB => '度数',
COLOR => 'BLUE',
);
my $data = grandom(10000); # 平均ゼロ、標準偏差1の乱数
my $nbins = 30;
my $binwidth = ($data->max - $data->min) / $nbins;
my ($x, $y) = hist($data, $data->minmax, $binwidth);
$pl->histogram($data, $nbins, BOX => [ $x->minmax, 0, $y->max * 1.1 ]);
$pl->close;
2014/05/27(火)Perl Data Language 基礎編 #08 「データフロー」
データフローは、多数のピドルの間をデータが流れるようにするため、ピドル同士を結びつける概念です。たとえば、大きいデータ配列のピドルから部分的にデータを抜き出したピドルに変更を加えたりすると、その変更が元のピドルにも伝染します。
一般的にPDLの要素選択演算子(sliceやindex)は明白に切断しない限りデータフローコネクションが維持されます。データフローをサポートするため、PDLには2つの異なる代入方法があります。1つがグローバル代入演算子の「=」でもう1つが計算代入演算子の「.=」です。グローバル代入演算子は新しいピドルを作るのに使われ、計算代入演算子はすでに存在するピドルに値を挿入するのに使われます。
78行目でデータフローコネクションが作られないのは、「*」でコピーが生成されるためだと思います。混乱を避けるためには明示的にcopyメソッドを使うほうがいいかな。
#!/usr/bin/env perl
use strict;
use warnings;
use feature qw/say/;
use PDL;
use PDL::NiceSlice;
my $a = pdl [ 1 .. 5 ];
say "$a $a";
print "\n";
say "グローバル代入";
my $b = $a(2); # スライスしたのをグローバル代入
$b++;
say "$a $a";
say "$b $b";
print "\n";
say "計算代入";
$b .= 100; # 計算代入
say "$a $a";
say "$b $b";
print "n";
say "スカラーではデータフローコネクションは維持されないことを確認";
for my $i ($a->listindices)
{
my $tmp = $a->at($i);
$tmp++;
}
for my $elem ($a->list)
{
$elem++;
}
say "$a $a";
say "$b $b";
print "\n";
say "データフローコネクションの切断";
my $c = pdl [ 6 .. 10 ];
my $d = $c(2)->copy; # 物理コピー(コネクションは維持されない)
$d .= 555;
my $e = $c(2)->sever; # データフローコネクションの明示的な切断
$e .= 777;
say "$c $c";
say "$d $d";
say "$e $e";
my $f = $c->sever; # severはデータフローコネクションが作られていないものに対しては作用しない
$f += 100;
say "$c $c";
print "\n";
say "スライスしない場合のデータフローの確認";
my $g = pdl [ 1, 2, 3 ];
say "$g $g";
my $h = $g;
$h += 1000;
say "$g $g";
say "$h $h";
my $i = PDL->null;
$i .= $g;
$i += 1000;
say "$g $g";
say "$i $i";
my $k = pdl [ 8, 7, 3, 9 ];
my $l = $k * 2;
$l += 1000;
say "$k = $k";
say "$l = $l";
$k += 10;
say "$k = $k";
say "$l = $l";
実行結果↓
$a [1 2 3 4 5]
グローバル代入
$a [1 2 4 4 5]
$b [4]
計算代入
$a [1 2 100 4 5]
$b [100]
スカラーではデータフローコネクションは維持されないことを確認
$a [1 2 100 4 5]
$b [100]
データフローコネクションの切断
$c [6 7 8 9 10]
$d [555]
$e [777]
$c [106 107 108 109 110]
スライスしない場合のデータフローの確認
$g [1 2 3]
$g [1001 1002 1003]
$h [1001 1002 1003]
$g [1001 1002 1003]
$i [2001 2002 2003]
$k = [8 7 3 9]
$l = [1016 1014 1006 1018]
$k = [18 17 13 19]
$l = [1016 1014 1006 1018]